#Jabil
CNET’s highlights of Build 2018…
Reply

#Jabil
Jabil provides advanced manufacturing solutions that require visual inspection of components on production lines. Their pilot with Azure Machine Learning and Project Brainwave promises dramatic improvements in speed and accuracy, reducing workload and improving focus for human operators.
Proud to be the lead architect working on advanced Machine Learning solutions and pipelines at Jabil.
Sometimes working on advanced technologies comes with the peril of NDAs … which limit what I can talk about… but it is nice to see yet another of our projects feature in Keynote speech by Satya Nadella, this time at Microsoft //BUILD 2018. Proud to be the lead architect working on advanced Machine Learning solutions and pipelines at Jabil.
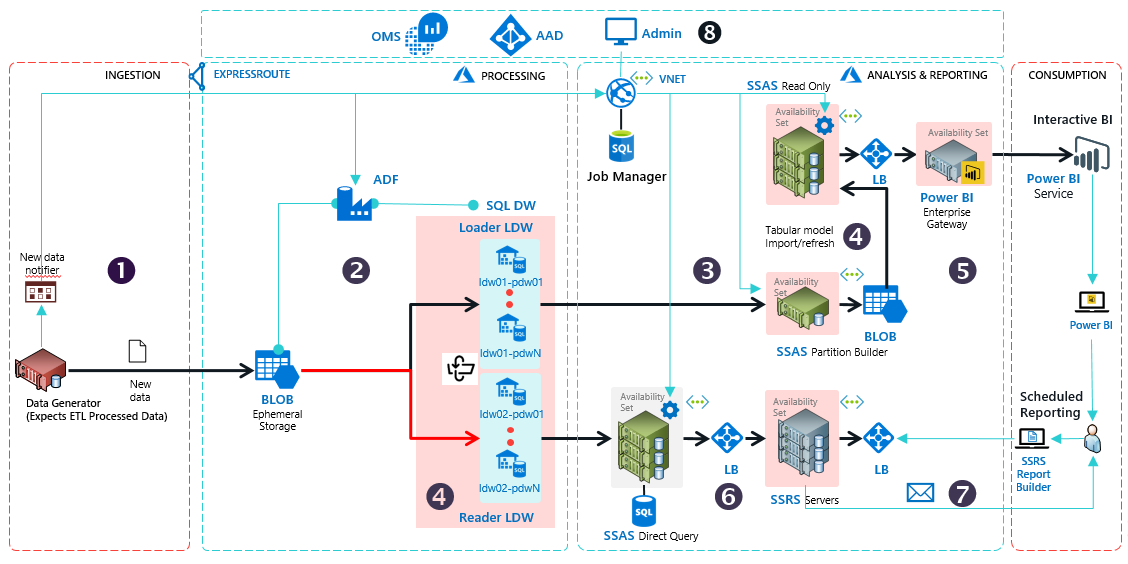
Azure offers a rich data and analytics platform for customers and ISVs seeking to build scalable BI and reporting solutions. However, customers face pragmatic challenges in building the right infrastructure for enterprise-grade production systems. They have to evaluate the various products for security, scale, performance and geo-availability requirements. They have to understand service features and their interoperability, and they must plan to address any perceived gaps using custom software. This takes time, effort, and many times, the end-to-end system architecture they design is sub-optimal.
ref: https://github.com/Azure/azure-arch-enterprise-bi-and-reporting/blob/master/README.md
Azure Cosmos DB, Azure DW, Machine Leaning, Deep Learning, Neural Networks, TensorFlow, SQL Server, ASP.NET Core… are just a few of the components that make up one of the solutions we are currently developing.
Have been under a social media embargo, until today, but now that the Microsoft Ignite 2017 keynote has taken place, I am able to proudly say that the solution our team has been working on for some time was part of the Keynote addresses.
During the second keynote lead by Scott Guthrie, Danielle Dean a Data Scientist Lead @Microsoft discussed at a high level, one of the solutions we are developing at Jabil, which involves advanced image recognition of circuit board issues. The keynote focused in on the context of the solutions data science portion and introduced the new Azure Machine Learning Workbench to the packed audience.
Tomorrow morning there is a session – “Using big data, the cloud, and AI to enable intelligence at scale” (Tuesday, September 26, from 9:00 AM to 10:15 AM, in Hyatt Regency Windermere X)… during which we will be going into a bit more detail, and the guys at Microsoft will be expanding on the new AI and Big Data machine learning capabilities (session details via this link).






Some cool stuff ahead today… keynote coming up…




Many database systems have features allowing change data capture or mirroring, for use with live backups, reporting, data warehousing and real time analytics for transactional systems… Azure Cosmos DB has such a feature called the Change Feed API, which was first introduced in May 2017.
The Change Feed API provides a list of new and updated documents in a partition in the order in which the updates were made.
Microsoft has just recently introduced the new Change Feed Processor Library which abstracts the existing Change Feed API to facilitate the distribution of change feed event processing across multiple consumers.
The Change Feed Processor library provides a thread-safe, multiple-process, runtime environment with checkpoint and partition lease management for change feed operations.
The Change Feed Processor Library is available as a NuGet package for .NET development. The library makes actions like these easier to read changes from a change feed across multiple partitions and performing computational actions triggered by the change feed in parallel (aka Complex Event Processing).
Judy Shen from the Microsoft Cosmos DB team has published some sample code on GitHub, demonstrating it’s use.
Aravind Ramachandran, Mimi Gentz and Judy Shen also just published an article Working with the change feed support in Azure Cosmos DB on the Azure docs site a few days ago…
2017-7-24
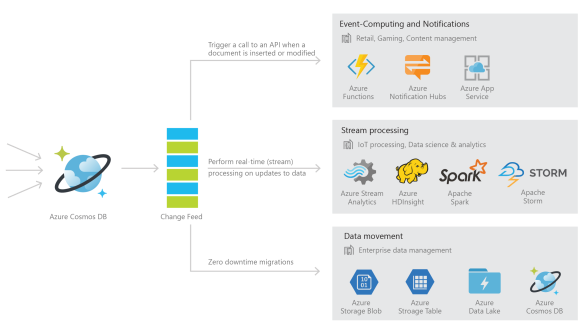
Azure Cosmos DB is a fast and flexible globally replicated database service that is used for storing high-volume transactional and operational data with predictable single-digit millisecond latency for reads and writes. This makes it well-suited for IoT, gaming, retail, and operational logging applications. A common design pattern in these applications is to track changes made to Azure Cosmos DB data, and update materialized views, perform real-time analytics, archive data to cold storage, and trigger notifications on certain events based on these changes. The change feed support in Azure Cosmos DB enables you to build efficient and scalable solutions for each of these patterns.
With change feed support, Azure Cosmos DB provides a sorted list of documents within an Azure Cosmos DB collection in the order in which they were modified. This feed can be used to listen for modifications to data within the collection and perform actions such as:
- Trigger a call to an API when a document is inserted or modified
- Perform real-time (stream) processing on updates
- Synchronize data with a cache, search engine, or data warehouse
Changes in Azure Cosmos DB are persisted and can be processed asynchronously, and distributed across one or more consumers for parallel processing. Let’s look at the APIs for change feed and how you can use them to build scalable real-time applications. This article shows how to work with Azure Cosmos DB change feed and the DocumentDB API.
Note
Change feed support is only provided for the DocumentDB API at this time; the Graph API and Table API are not currently supported.Use cases and scenarios
Change feed allows for efficient processing of large datasets with a high volume of writes, and offers an alternative to querying entire datasets to identify what has changed. For example, you can perform the following tasks efficiently:
- Update a cache, search index, or a data warehouse with data stored in Azure Cosmos DB.
- Implement application-level data tiering and archival, that is, store “hot data” in Azure Cosmos DB, and age out “cold data” to Azure Blob Storage or Azure Data Lake Store.
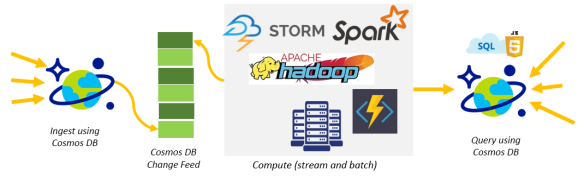
- Implement batch analytics on data using Apache Hadoop.
- Implement lambda pipelines on Azure with Azure Cosmos DB. Azure Cosmos DB provides a scalable database solution that can handle both ingestion and query, and implement lambda architectures with low TCO.
- Perform zero down-time migrations to another Azure Cosmos DB account with a different partitioning scheme.
Lambda Pipelines with Azure Cosmos DB for ingestion and query
You can use Azure Cosmos DB to receive and store event data from devices, sensors, infrastructure, and applications, and process these events in real-time with Azure Stream Analytics, Apache Storm, or Apache Spark.
Within web and mobile apps, you can track events such as changes to your customer’s profile, preferences, or location to trigger certain actions like sending push notifications to their devices using Azure Functions or App Services. If you’re using Azure Cosmos DB to build a game, you can, for example, use change feed to implement real-time leaderboards based on scores from completed games.
…
Read more at https://docs.microsoft.com/en-gb/azure/cosmos-db/change-feed
–
 Enabling Fast, Efficient, and Reproducible Results for Data Science • via GitHub
Enabling Fast, Efficient, and Reproducible Results for Data Science • via GitHubGitHub partnered with O’Reilly Media to examine how data science and analytics teams at several data-driven organizations are improving the way they define, enforce, and automate development workflows.
Download this complimentary book from: – https://resources.github.com/whitepapers/data-science/
Visualize business process workflows, real-world layouts like factory floor plans, network diagrams, organization structures or any illustration created in Microsoft Visio and easily connect it to Power BI data. Contextually represent Power BI data as colours or text on Visio diagrams. Now drive Operational Intelligence effectively using Visio custom visual.

Posted July 23, 2017 | by Microsoft Research Blog
By Marc Pollefeys, Director of Science, HoloLens
It is not an exaggeration to say that deep learning has taken the world of computer vision, and many other recognition tasks, by storm. Many of the most difficult recognition problems have seen gains over the past few years that are astonishing.
Although we have seen large improvements in the accuracy of recognition as a result of Deep Neural Networks (DNNs), deep learning approaches have two well-known challenges: they require large amounts of labelled data for training, and they require a type of compute that is not amenable to current general purpose processor/memory architectures. Some companies have responded with architectures designed to address the particular type of massively parallel compute required for DNNs, including our own use of FPGAs, for example, but to date these approaches have primarily enhanced existing cloud computing fabrics.
But I work on HoloLens, and in HoloLens, we’re in the business of making untethered mixed reality devices. We put the battery on your head, in addition to the compute, the sensors, and the display. Any compute we want to run locally for low-latency, which you need for things like hand-tracking, has to run off the same battery that powers everything else. So what do you do?
You create custom silicon to do it.
First, a bit of background. HoloLens contains a custom multiprocessor called the Holographic Processing Unit, or HPU. It is responsible for processing the information coming from all of the on-board sensors, including Microsoft’s custom time-of-flight depth sensor, head-tracking cameras, the inertial measurement unit (IMU), and the infrared camera. The HPU is part of what makes HoloLens the world’s first–and still only–fully self-contained holographic computer.
Today, Harry Shum, executive vice president of our Artificial Intelligence and Research Group, announced in a keynote speech at CVPR 2017, that the second version of the HPU, currently under development, will incorporate an AI coprocessor to natively and flexibly implement DNNs. The chip supports a wide variety of layer types, fully programmable by us. Harry showed an early spin of the second version of the HPU running live code implementing hand segmentation.
The AI coprocessor is designed to work in the next version of HoloLens, running continuously, off the HoloLens battery. This is just one example of the new capabilities we are developing for HoloLens, and is the kind of thing you can do when you have the willingness and capacity to invest for the long term, as Microsoft has done throughout its history. And this is the kind of thinking you need if you’re going to develop mixed reality devices that are themselves intelligent. Mixed reality and artificial intelligence represent the future of computing, and we’re excited to be advancing this frontier.