#Jabil
CNET’s highlights of Build 2018…
Reply

#Jabil
Jabil provides advanced manufacturing solutions that require visual inspection of components on production lines. Their pilot with Azure Machine Learning and Project Brainwave promises dramatic improvements in speed and accuracy, reducing workload and improving focus for human operators.
Proud to be the lead architect working on advanced Machine Learning solutions and pipelines at Jabil.
Sometimes working on advanced technologies comes with the peril of NDAs … which limit what I can talk about… but it is nice to see yet another of our projects feature in Keynote speech by Satya Nadella, this time at Microsoft //BUILD 2018. Proud to be the lead architect working on advanced Machine Learning solutions and pipelines at Jabil.
“Azure SQL Data Sync allows users to synchronize data between Azure SQL Databases and SQL Server databases in one-direction or bi-direction. This feature was first introduced in 2012. By that time, people didn’t host a lot of large databases in Azure. Some size limitations were applied when we built the data sync service, including up to 30 databases (five on-premises SQL Server databases) in a single sync group, and up to 500 tables in any database in a sync group.
Today, there are more than two million Azure SQL Databases and the maximum database size is 4TB. But those limitations of data sync are still there. It is mainly because that syncing data is a size of data operation. Without an architectural change, we can’t ensure the service can sustain the heavy load when syncing in a large scale. We are working on some improvements in this area. Some of these limitations will be raised or removed in the future. In this article, we are going to show you how to use data sync to sync data between large number of databases and tables, including some best practices and how to temporarily work around database and table limitations”…
Read more at https://azure.microsoft.com/en-gb/blog/sync-sql-data-in-large-scale-using-azure-sql-data-sync/

https://docs.microsoft.com/en-us/azure/event-grid/overview

Azure Event Grid generally available
Easily subscribe and react to interesting events happening in any Azure service or in your own apps with Azure Event Grid, a fully managed event routing service. Event Grid removes the need to continuously poll by reliably routing events at high scale and low latency. In addition, take advantage of the rich coverage and reactive event model enabled by Event Grid in your serverless architectures. These features were added as part of the general availability (GA) release:
| ✓ | Richer scenarios enabled through integration with more services: Azure Storage General Purpose v2 accounts were added; Azure IoT Hub and Azure Service Bus were added as new event publishers; and Azure Event Hubs was added as a new destination for events. |
| ✓ | Availability in more regions: It’s now available in the following regions: West US, East US, West US 2, East US 2, West Central US, Central US, West Europe, North Europe, Southeast Asia, and East Asia, with more coming soon. |
| ✓ | Increased reliability and service-level agreement (SLA): We now have a 24-hour retry policy with exponential back off for event delivery. We also offer 99.99 percent availability with a financially backed SLA for your production workloads. |
| ✓ | Better developer productivity: New management and data plane SDKs help make the development process smoother. |
Event Grid is now generally available. GA pricing will be effective for billing periods beginning on or after April 1, 2018. Learn more on the overview and pricing webpages or via the Azure Blog.
The Azure Data Architecture Guide:
The guide is structured around a basic pivot: The distinction between relational data and non-relational data.
Relational data is generally stored in a traditional RDBMS or a data warehouse. It has a pre-defined schema (“schema on write”) with a set of constraints to maintain referential integrity. Most relational databases use Structured Query Language (SQL) for querying. Solutions that use relational databases include online transaction processing (OLTP) and online analytical processing (OLAP).
Non-relational data is any data that does not use the relational model found in traditional RDBMS systems. This may include key-value data, JSON data, graph data, time series data, and other data types. The term NoSQL refers to databases that are designed to hold various types of non-relational data. However, the term is not entirely accurate, because many non-relational data stores support SQL compatible queries. Non-relational data and NoSQL databases often come up in discussions of big data solutions. A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional database systems.
Within each of these two main categories, the Data Architecture Guide contains the following sections:
This guide is not intended to teach you data science or database theory — you can find entire books on those subjects. Instead, the goal is to help you select the right data architecture or data pipeline for your scenario, and then select the Azure services and technologies that best fit your requirements. If you already have an architecture in mind, you can skip directly to the technology choices.
Traditional RDBMS
Concepts
Scenarios
Big data and NoSQL
Concepts
Scenarios
Cross-cutting concerns
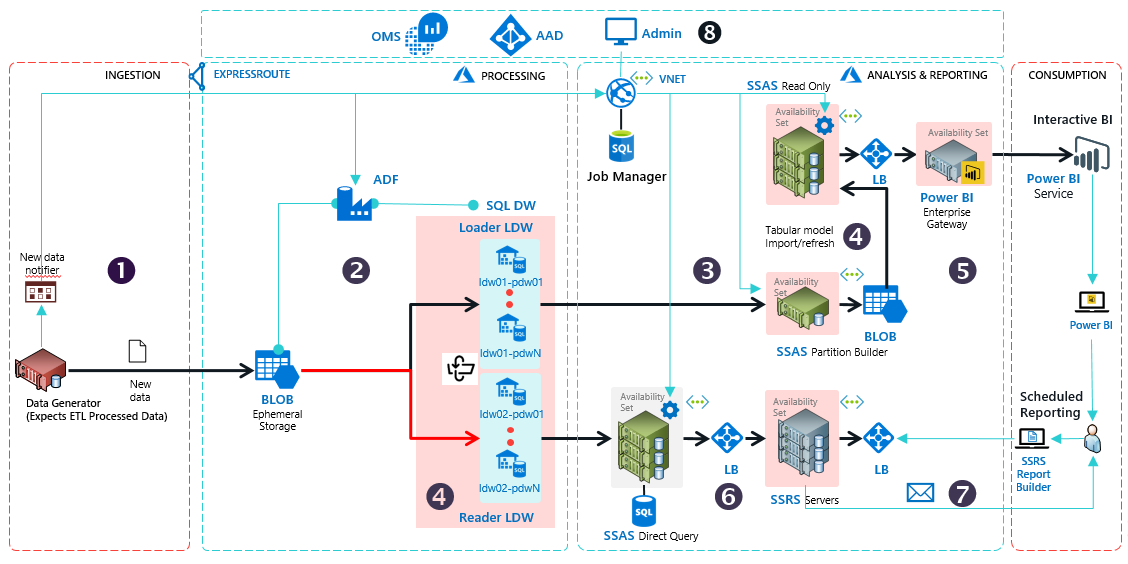
Azure offers a rich data and analytics platform for customers and ISVs seeking to build scalable BI and reporting solutions. However, customers face pragmatic challenges in building the right infrastructure for enterprise-grade production systems. They have to evaluate the various products for security, scale, performance and geo-availability requirements. They have to understand service features and their interoperability, and they must plan to address any perceived gaps using custom software. This takes time, effort, and many times, the end-to-end system architecture they design is sub-optimal.
ref: https://github.com/Azure/azure-arch-enterprise-bi-and-reporting/blob/master/README.md
Since there seemed to be limited answers out there I decided to blog about a system installation issue I ran into…
Ran into a few problems recently after deciding to upgrade the SSD in a new HP Spectre x360. The supplied drive was a 512GB, and was upgrading it to 1TB, as 512GB is a little on the low side for the work I do.
Having taken backups and replaced the old drive, I proceeded to install from a standard ISO pushed onto a USB.
The default settings (UEFI enabled) refused to see the standard ISO for Windows 10 Pro, so I had to switch it to legacy mode (which disables secure boot), within the BIOS. This allowed the USB to be detected and install to go smoothly.
Cut to install completed, and system running smoothly… for my work I must enable BitLocker and encrypt my drive… going through the options the verification check fails…

The BitLocker encryption key cannot be obtained from the Trusted Platform Module (TPM).
I can force enable BitLocker but TPM will not function properly and I have to enter the decryption key every time I start the computer.
UEFI is still disabled.
”TPM.msc” (through start menu) and “get-tpm” (through an admin PowerShell) confirm that TPM is enabled but operating with reduced functionality and not ready for full use.
A quick check seems to indicate that TPM 1.2 is OK with legacy boot mode, but TPM 2.0 (as in my new system) requires UEFI to be enabled, along with secure boot for TPM to fully function.
Enabling UEFI obviously fails to recognise the drive, since it was installed with legacy mode which installs it with MBR (master boot record), as opposed to the UEFI requirement of GPT (GUID partition table).
Incidentally with TPM operating in a diminished mode, Hyper-V cannot use TPM and will fail on any encrypted VMs (also a requirement for me).
Checking the HP Support site; their only recommendation is to pay them for the HP install media, which will install their version of the OS along with all their utilities and bloatware… erm no thanks!
Some light research showed that I could create my own UEFI boot media using Rufus… Rufus is an open source stand alone EXE that you can run locally – full details can b found here – https://github.com/pbatard/rufus/wiki/FAQ and can be downloaded from http://rufus.akeo.ie/downloads/

However, having already completed the installation, wanted to avoid this if I could.
… what to do …
Well, Microsoft to the rescue. The latest version of Windows 10 now includes a new tool, which allows a MBR install to be converted to GPT with one line from Command Prompt… the tool has additional abilities also.
The following command run from an elevated (administrator) command prompt will allow you to convert the current disk to GPT.
C:\WINDOWS\system32\mbr2gpt.exe /convert /allowFullOS

MBR2GPT.EXE converts a disk from the Master Boot Record (MBR) to the GUID Partition Table (GPT) partition style without modifying or deleting data on the disk. The tool is designed to be run from a Windows Preinstallation Environment (Windows PE) command prompt, but can also be run from the full Windows 10 operating system (OS) by using the /allowFullOS option.
After conversion is completed (for me it only took a few seconds), you need to reboot and change your BIOS settings to re-enable/enable UEFI along with secure boot.
Full details of MBR2GPT may be found here – https://docs.microsoft.com/en-us/windows/deployment/mbr-to-gpt
You should then find that TPM is functional again…
… however if still having issues… you should clear and prepare TPM by i) opening up TPM.msc, ii) “Clear TPM”, iii) reboot, iv) open TPM.msc again and then v) choose “Prepare the TPM”.

After jumping through a few hoops I was able to successfully encrypt my drive and then enable TPM encryption within Hyper-V.

BitLocker Enabled – note: you can open TPM.msc from start menu (by typing TPM.msc) or from BitLocker window (“TPM Administrator”).
Azure Cosmos DB, Azure DW, Machine Leaning, Deep Learning, Neural Networks, TensorFlow, SQL Server, ASP.NET Core… are just a few of the components that make up one of the solutions we are currently developing.
Have been under a social media embargo, until today, but now that the Microsoft Ignite 2017 keynote has taken place, I am able to proudly say that the solution our team has been working on for some time was part of the Keynote addresses.
During the second keynote lead by Scott Guthrie, Danielle Dean a Data Scientist Lead @Microsoft discussed at a high level, one of the solutions we are developing at Jabil, which involves advanced image recognition of circuit board issues. The keynote focused in on the context of the solutions data science portion and introduced the new Azure Machine Learning Workbench to the packed audience.
Tomorrow morning there is a session – “Using big data, the cloud, and AI to enable intelligence at scale” (Tuesday, September 26, from 9:00 AM to 10:15 AM, in Hyatt Regency Windermere X)… during which we will be going into a bit more detail, and the guys at Microsoft will be expanding on the new AI and Big Data machine learning capabilities (session details via this link).






Some cool stuff ahead today… keynote coming up…




