Cosmos DB Change Feed Processor NuGet package now available
Many database systems have features allowing change data capture or mirroring, for use with live backups, reporting, data warehousing and real time analytics for transactional systems… Azure Cosmos DB has such a feature called the Change Feed API, which was first introduced in May 2017.
The Change Feed API provides a list of new and updated documents in a partition in the order in which the updates were made.
Microsoft has just recently introduced the new Change Feed Processor Library which abstracts the existing Change Feed API to facilitate the distribution of change feed event processing across multiple consumers.
The Change Feed Processor library provides a thread-safe, multiple-process, runtime environment with checkpoint and partition lease management for change feed operations.
The Change Feed Processor Library is available as a NuGet package for .NET development. The library makes actions like these easier to read changes from a change feed across multiple partitions and performing computational actions triggered by the change feed in parallel (aka Complex Event Processing).
Judy Shen from the Microsoft Cosmos DB team has published some sample code on GitHub, demonstrating it’s use.
Working with the change feed support in Azure Cosmos DB
Aravind Ramachandran, Mimi Gentz and Judy Shen also just published an article Working with the change feed support in Azure Cosmos DB on the Azure docs site a few days ago…
2017-7-24
Azure Cosmos DB is a fast and flexible globally replicated database service that is used for storing high-volume transactional and operational data with predictable single-digit millisecond latency for reads and writes. This makes it well-suited for IoT, gaming, retail, and operational logging applications. A common design pattern in these applications is to track changes made to Azure Cosmos DB data, and update materialized views, perform real-time analytics, archive data to cold storage, and trigger notifications on certain events based on these changes. The change feed support in Azure Cosmos DB enables you to build efficient and scalable solutions for each of these patterns.
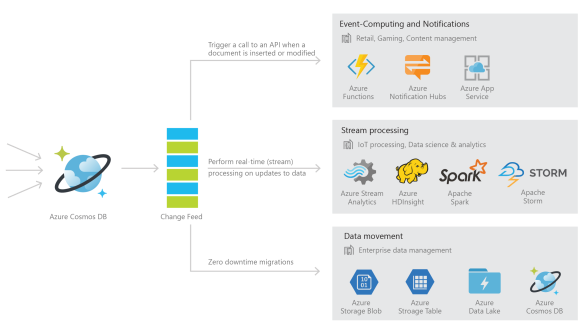
With change feed support, Azure Cosmos DB provides a sorted list of documents within an Azure Cosmos DB collection in the order in which they were modified. This feed can be used to listen for modifications to data within the collection and perform actions such as:
- Trigger a call to an API when a document is inserted or modified
- Perform real-time (stream) processing on updates
- Synchronize data with a cache, search engine, or data warehouse
Changes in Azure Cosmos DB are persisted and can be processed asynchronously, and distributed across one or more consumers for parallel processing. Let’s look at the APIs for change feed and how you can use them to build scalable real-time applications. This article shows how to work with Azure Cosmos DB change feed and the DocumentDB API.
Note
Change feed support is only provided for the DocumentDB API at this time; the Graph API and Table API are not currently supported.
Use cases and scenarios
Change feed allows for efficient processing of large datasets with a high volume of writes, and offers an alternative to querying entire datasets to identify what has changed. For example, you can perform the following tasks efficiently:
- Update a cache, search index, or a data warehouse with data stored in Azure Cosmos DB.
- Implement application-level data tiering and archival, that is, store “hot data” in Azure Cosmos DB, and age out “cold data” to Azure Blob Storage or Azure Data Lake Store.
- Implement batch analytics on data using Apache Hadoop.
- Implement lambda pipelines on Azure with Azure Cosmos DB. Azure Cosmos DB provides a scalable database solution that can handle both ingestion and query, and implement lambda architectures with low TCO.
- Perform zero down-time migrations to another Azure Cosmos DB account with a different partitioning scheme.
Lambda Pipelines with Azure Cosmos DB for ingestion and query
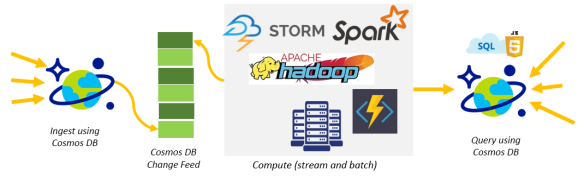
You can use Azure Cosmos DB to receive and store event data from devices, sensors, infrastructure, and applications, and process these events in real-time with Azure Stream Analytics, Apache Storm, or Apache Spark.
Within web and mobile apps, you can track events such as changes to your customer’s profile, preferences, or location to trigger certain actions like sending push notifications to their devices using Azure Functions or App Services. If you’re using Azure Cosmos DB to build a game, you can, for example, use change feed to implement real-time leaderboards based on scores from completed games.
…
Read more at https://docs.microsoft.com/en-gb/azure/cosmos-db/change-feed
–









 New update for Azure SQL Data Warehouse…
New update for Azure SQL Data Warehouse…

