#Jabil
CNET’s highlights of Build 2018…
Reply

#Jabil
Jabil provides advanced manufacturing solutions that require visual inspection of components on production lines. Their pilot with Azure Machine Learning and Project Brainwave promises dramatic improvements in speed and accuracy, reducing workload and improving focus for human operators.
Proud to be the lead architect working on advanced Machine Learning solutions and pipelines at Jabil.
Sometimes working on advanced technologies comes with the peril of NDAs … which limit what I can talk about… but it is nice to see yet another of our projects feature in Keynote speech by Satya Nadella, this time at Microsoft //BUILD 2018. Proud to be the lead architect working on advanced Machine Learning solutions and pipelines at Jabil.
“Azure SQL Data Sync allows users to synchronize data between Azure SQL Databases and SQL Server databases in one-direction or bi-direction. This feature was first introduced in 2012. By that time, people didn’t host a lot of large databases in Azure. Some size limitations were applied when we built the data sync service, including up to 30 databases (five on-premises SQL Server databases) in a single sync group, and up to 500 tables in any database in a sync group.
Today, there are more than two million Azure SQL Databases and the maximum database size is 4TB. But those limitations of data sync are still there. It is mainly because that syncing data is a size of data operation. Without an architectural change, we can’t ensure the service can sustain the heavy load when syncing in a large scale. We are working on some improvements in this area. Some of these limitations will be raised or removed in the future. In this article, we are going to show you how to use data sync to sync data between large number of databases and tables, including some best practices and how to temporarily work around database and table limitations”…
Read more at https://azure.microsoft.com/en-gb/blog/sync-sql-data-in-large-scale-using-azure-sql-data-sync/

https://docs.microsoft.com/en-us/azure/event-grid/overview

Azure Event Grid generally available
Easily subscribe and react to interesting events happening in any Azure service or in your own apps with Azure Event Grid, a fully managed event routing service. Event Grid removes the need to continuously poll by reliably routing events at high scale and low latency. In addition, take advantage of the rich coverage and reactive event model enabled by Event Grid in your serverless architectures. These features were added as part of the general availability (GA) release:
| ✓ | Richer scenarios enabled through integration with more services: Azure Storage General Purpose v2 accounts were added; Azure IoT Hub and Azure Service Bus were added as new event publishers; and Azure Event Hubs was added as a new destination for events. |
| ✓ | Availability in more regions: It’s now available in the following regions: West US, East US, West US 2, East US 2, West Central US, Central US, West Europe, North Europe, Southeast Asia, and East Asia, with more coming soon. |
| ✓ | Increased reliability and service-level agreement (SLA): We now have a 24-hour retry policy with exponential back off for event delivery. We also offer 99.99 percent availability with a financially backed SLA for your production workloads. |
| ✓ | Better developer productivity: New management and data plane SDKs help make the development process smoother. |
Event Grid is now generally available. GA pricing will be effective for billing periods beginning on or after April 1, 2018. Learn more on the overview and pricing webpages or via the Azure Blog.
The Azure Data Architecture Guide:
The guide is structured around a basic pivot: The distinction between relational data and non-relational data.
Relational data is generally stored in a traditional RDBMS or a data warehouse. It has a pre-defined schema (“schema on write”) with a set of constraints to maintain referential integrity. Most relational databases use Structured Query Language (SQL) for querying. Solutions that use relational databases include online transaction processing (OLTP) and online analytical processing (OLAP).
Non-relational data is any data that does not use the relational model found in traditional RDBMS systems. This may include key-value data, JSON data, graph data, time series data, and other data types. The term NoSQL refers to databases that are designed to hold various types of non-relational data. However, the term is not entirely accurate, because many non-relational data stores support SQL compatible queries. Non-relational data and NoSQL databases often come up in discussions of big data solutions. A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional database systems.
Within each of these two main categories, the Data Architecture Guide contains the following sections:
This guide is not intended to teach you data science or database theory — you can find entire books on those subjects. Instead, the goal is to help you select the right data architecture or data pipeline for your scenario, and then select the Azure services and technologies that best fit your requirements. If you already have an architecture in mind, you can skip directly to the technology choices.
Traditional RDBMS
Concepts
Scenarios
Big data and NoSQL
Concepts
Scenarios
Cross-cutting concerns
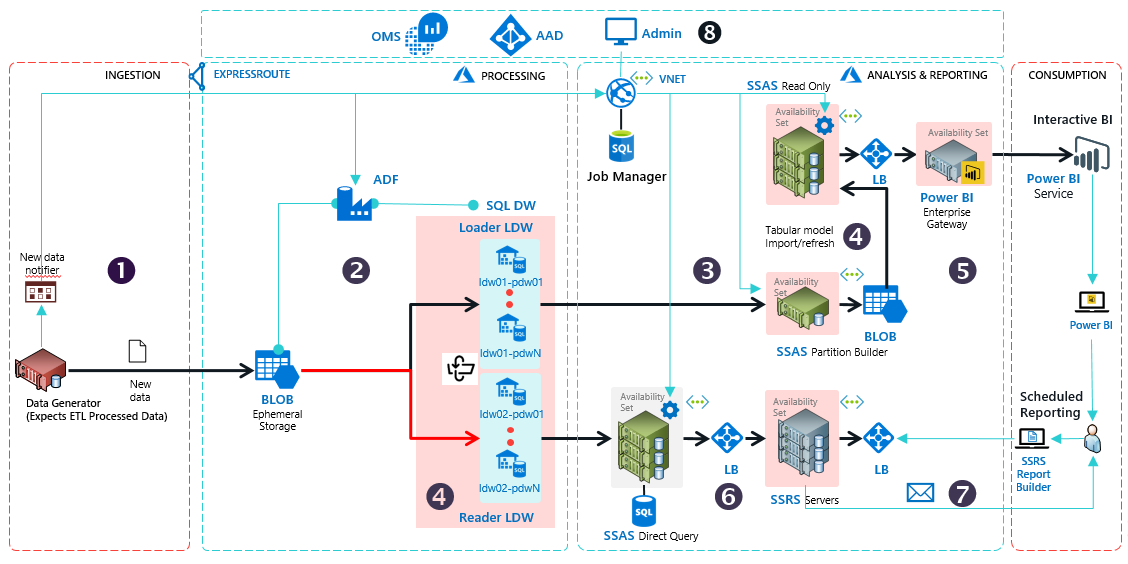
Azure offers a rich data and analytics platform for customers and ISVs seeking to build scalable BI and reporting solutions. However, customers face pragmatic challenges in building the right infrastructure for enterprise-grade production systems. They have to evaluate the various products for security, scale, performance and geo-availability requirements. They have to understand service features and their interoperability, and they must plan to address any perceived gaps using custom software. This takes time, effort, and many times, the end-to-end system architecture they design is sub-optimal.
ref: https://github.com/Azure/azure-arch-enterprise-bi-and-reporting/blob/master/README.md
Azure Cosmos DB, Azure DW, Machine Leaning, Deep Learning, Neural Networks, TensorFlow, SQL Server, ASP.NET Core… are just a few of the components that make up one of the solutions we are currently developing.
Have been under a social media embargo, until today, but now that the Microsoft Ignite 2017 keynote has taken place, I am able to proudly say that the solution our team has been working on for some time was part of the Keynote addresses.
During the second keynote lead by Scott Guthrie, Danielle Dean a Data Scientist Lead @Microsoft discussed at a high level, one of the solutions we are developing at Jabil, which involves advanced image recognition of circuit board issues. The keynote focused in on the context of the solutions data science portion and introduced the new Azure Machine Learning Workbench to the packed audience.
Tomorrow morning there is a session – “Using big data, the cloud, and AI to enable intelligence at scale” (Tuesday, September 26, from 9:00 AM to 10:15 AM, in Hyatt Regency Windermere X)… during which we will be going into a bit more detail, and the guys at Microsoft will be expanding on the new AI and Big Data machine learning capabilities (session details via this link).






Some cool stuff ahead today… keynote coming up…




Issues Fixed in August 18, 2017 Release
These are the customer-reported issues addressed in this version:
- Update Git version to address security fix.
- Add Watch displays the wrong line of code.
- F# Editor loses focus when typing arrow, backspace, or newline keys.
- R Tools missing translations.
Summary: What’s New in this Release
- Accessibility Improvements make Visual Studio more accessible than ever.
- Azure Function Tools are included in the Azure development workload. You can develop Azure Function applications locally and publish directly to Azure.
- You can now build applications in Visual Studio 2017 that run on Azure Stack and government clouds, like Azure in China.
- We improved .NET Core development support for .NET Core 2.0, and Windows Nano Server containers.
- In Visual Studio IDE, we improved Sign In and Identity, the start page, Lightweight Solution Load, and setup CLI. We also improved refactoring, code generation and Quick Actions.
- The Visual Studio Editor has better accessibility due to the new ‘Blue (Extra Contrast)’ theme and improved screen reader support.
- We improved the Debugger and diagnostics experience. This includes Point and Click to Set Next Statement. We’ve also refreshed all nested values in variable window, and made Open Folder debugging improvements.
- Xamarin has a new standalone editor for editing app entitlements.
- The Open Folder and CMake Tooling experience is updated. You can now use CMake 3.8.
- We made improvements to the IntelliSense engine, and to the project and the code wizards for C++ Language Services.
- Visual C++ Toolset supports command-prompt initialization targeting.
- We added the ability to use C# 7.1 Language features.
- You can install TypeScript versions independent of Visual Studio updates.
- We added support for Node 8 debugging.
- NuGet has added support for new TFMs (netcoreapp2.0, netstandard2.0, Tizen), Semantic Versioning 2.0.0, and MSBuild integration of NuGet warnings and errors.
- Visual Studio now offers .NET Framework 4.7 development tools to supported platforms with 4.7 runtime included.
- We added clusters of related events to the search query results in the Application Insights Search tool.
- We improved syntax support for SQL Server 2016 in Redgate SQL Search.
- We enabled support for Microsoft Graph APIs in Connected Services.
Read more at https://www.visualstudio.com/en-gb/news/releasenotes/vs2017-relnotes#15.3.26730.08
